歌唱音声合成におけるF0の自然性向上のためのDiffusion-GANモデルの検討
☆芦田 裕飛,中鹿 亘
概要: 歌唱音声合成においては,歌唱表現を再現することが求められる.
この歌唱表現は,ほぼ全てf0によって表現される.例えば,しゃくりやフォール,ビブラートなどの歌唱表現はほとんどf0の変化を指す.
歌う時々によってf0の変化は異なる上に,複雑な変化を伴うため,それらの表現を獲得するには,表現力の高いモデルを使用することが求められるが,速度と品質の両立が難しい.
本研究では,表現力の高いDiffusionとGANを組み合わせ,低ステップのデノイズでMel-spectrogramを生成できるDiffGAN-TTS [1]に着目し, Diffusion-GANを用いてf0を合成するモデルを提案・評価した.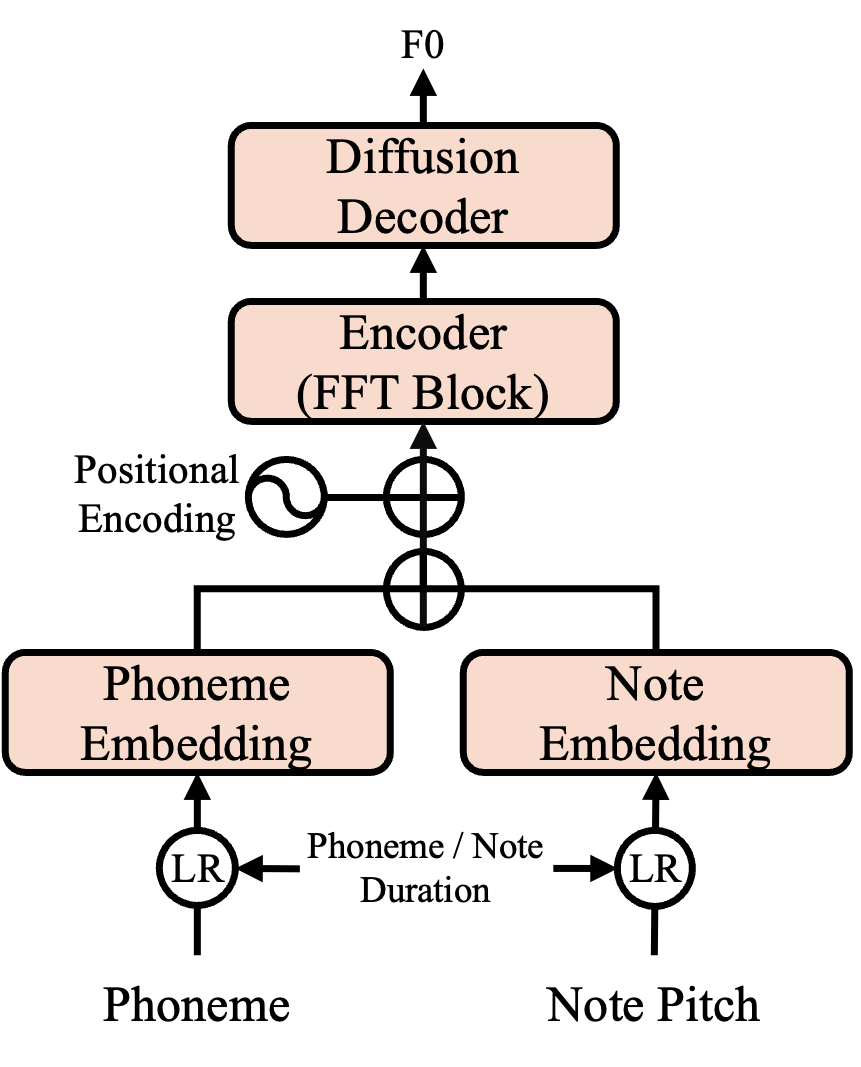
この歌唱表現は,ほぼ全てf0によって表現される.例えば,しゃくりやフォール,ビブラートなどの歌唱表現はほとんどf0の変化を指す.
歌う時々によってf0の変化は異なる上に,複雑な変化を伴うため,それらの表現を獲得するには,表現力の高いモデルを使用することが求められるが,速度と品質の両立が難しい.
本研究では,表現力の高いDiffusionとGANを組み合わせ,低ステップのデノイズでMel-spectrogramを生成できるDiffGAN-TTS [1]に着目し, Diffusion-GANを用いてf0を合成するモデルを提案・評価した.
図1: F0を合成するDiffusion-GANモデルのアーキテクチャ
生成結果・デモ音声
表示するデータ
Method | F0画像 | 合成音声 (SiFiSinger [2]) |
|---|---|---|
自然音声より抽出 | 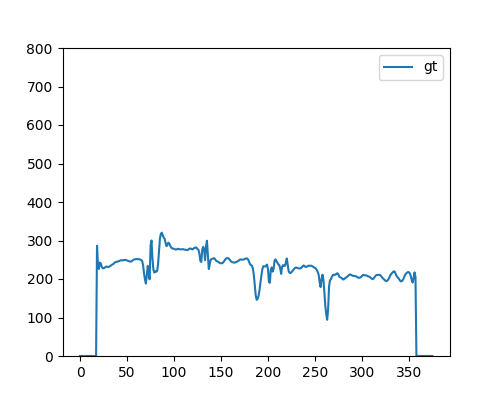 | |
CNN(Variance Predictor in FastSpeech 2) | 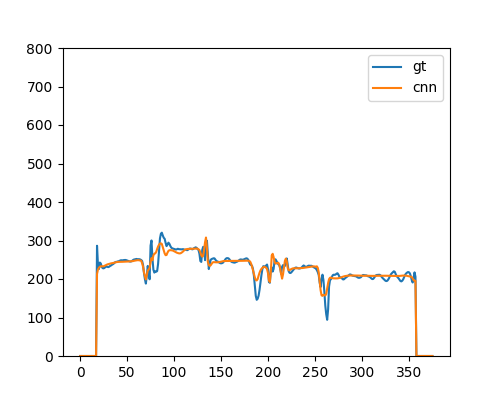 | |
P-DDPM(RMSSinger) | 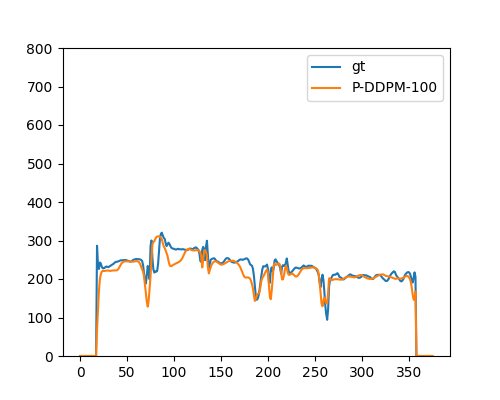 | |
P-DDPM(RMSSinger/4ステップ) | 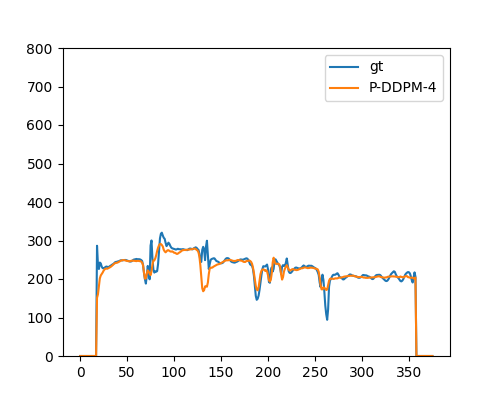 | |
提案手法 | 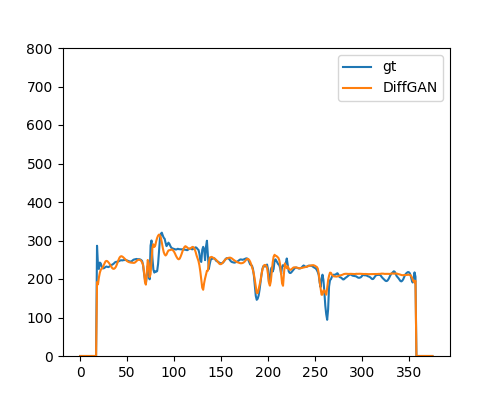 |